- Apa yang dimaksud Adversarial Search & Constraint Satisfaction Problems? berikan contoh?
– Adversarial Search
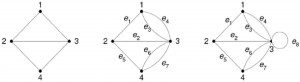
The search tree in adversarial games such as tic-tac-toe consist of alternating levels where the moving (MAX) player tries to maximize fitness and then the opposing (MIN) player tries to minimize it. To find the best move the system first generates all possible legal moves, and applies them to the current board. In a simple game like tic-tac-toe this process is repeated for each possible move until the game is won, lost, or drawn. The fitness of a top-level move is determined by whether it eventually leads to a win.
Contoh : Backgammon, Permainan kartu, Halma, Catur
– Constraint Satifaction Problems
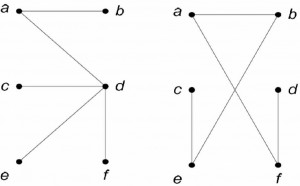
Search can be made easier in cases where the solution insted of corresponding to an optimal path, is only required to satisfy local consistency conditions. We call such problems Constraint Satisfaction (CS) Problems.
Contoh: teka teki silang
2.Apa itu Propositional Logic? berikan contoh?
Propositional (zeroth-order) logic is simply capable of making and verifying logical statements. First-order (and higher order) logics can represent proofs (or increasing hierarchial complexity) – true/false
Contoh :
– Tanjung karang berada di provinsi Lampung (Proposisi bernilai benar)
– Susilo Bambang Yudhoyono adalah presiden AS (Proposisi bernilai salah)
– 1 + 1 =2 (Proposisi bernilai benar)
– 2 + 2 = 3 (Proposisi bernilai salah)
3. Buat coding (Boleh C, C++ atau Java) untuk Algoritma A & Algoritma A* (A Star)?
Contoh algoritma A dalam Java
package hitungratarata5bil;
import java.io.*;
public class HitungRataRata5Bil {
public static void main(String[] args) {
double x = 0;
int a = 0;
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String strbilangan = null;
while (a < 5) {
System.out.print("Masukkan bilangan ke-" + a + " : ");
try {
strbilangan = br.readLine();
} catch (IOException ioe) {
System.out.println("Kesalahan IO, program berhenti");
System.exit(1);
}
x = x + Double.parseDouble(strbilangan);
a = a + 1;
}
x = x / 5;
System.out.println("Rata-rata bilangan yang dimasukkan adalah " + x);
}
}
Contoh algoritma A * dalam Java
import java.util.Iterator;
import java.util.LinkedList;
import java.util.PriorityQueue;
import java.util.Queue;
public class AStar {
private PriorityQueue<Node> openQ;
private Queue<Node> closedQ;
private int [][] map;
private int startX, startY, endX, endY;
private Node endNode;
public AStar(int[][]map, int startX, int startY, int endX, int endY) {
openQ = new PriorityQueue<Node>();
closedQ = new LinkedList<Node>();
this.map = map;
this.startX = startX;
this.startY = startY;
this.endX = endX;
this.endY = endY;
endNode = new Node(endX, endY, 0, null);
private int manhattanDist(Node curr, Node target) {
int cX, tX, cY, tY;
cX = curr.getX();
tX = target.getX();
cY = curr.getY();
tY = target.getY();
return 10*(Math.abs(cX – tX)+Math.abs(cY – tY));
}
private boolean onClosedList(Node node) {
if(closedQ.isEmpty() == true)
return false;
Iterator<Node> it = closedQ.iterator();
while(it.hasNext()) {
Node nodeCheck = it.next();
if(nodeCheck.getX() == node.getX() && nodeCheck.getY() == node.getY())
return true;
}
return false;
}
private boolean checkAndReplaceOpen(Node node, Node curr, boolean diag) { // true means replaced
Iterator<Node> it = openQ.iterator();
while(it.hasNext()) {
Node nodeCheck = it.next();
if(nodeCheck.getX() == node.getX() && nodeCheck.getY() == node.getY()) {
if(node.getG() < nodeCheck.getG()) {
if(diag == true)
node.setG(curr.getG()+14);
else
node.setG(curr.getG()+10);
node.setF(node.getG() + node.getH());
node.setParent(curr);
return true;
}
return false;
}
}
return false;
}
private void addNeighbors(Node node) {
int x = node.getX();
int y = node.getY();
if((x+1)< map[y].length && map[y][x+1] !=1) {
Node newNode = new Node(x+1, y, map[y][x+1], node);
if(onClosedList(newNode) == false) {
newNode.setG(node.getG()+10);
newNode.setH(manhattanDist(newNode, endNode));
newNode.setF(newNode.getG()+newNode.getH());
if(checkAndReplaceOpen(newNode, node, false) == false)
openQ.add(newNode);
}
}
if((x-1) >= 0 && map[y][x-1] !=1 ) {
Node newNode = new Node(x-1, y, map[y][x-1], node);
if(onClosedList(newNode) == false) {
newNode.setG(node.getG()+10);
newNode.setH(manhattanDist(newNode, endNode));
newNode.setF(newNode.getG()+newNode.getH());
if(checkAndReplaceOpen(newNode, node, false) == false)
openQ.add(newNode);
}
}
if((y+1) < map.length && map[y+1][x] !=1) {
Node newNode = new Node(x, y+1, map[y+1][x], node);
if(onClosedList(newNode) == false) {
newNode.setG(node.getG()+10);
newNode.setH(manhattanDist(newNode, endNode));
newNode.setF(newNode.getG()+newNode.getH());
if(checkAndReplaceOpen(newNode, node, false) == false)
openQ.add(newNode);
}
}
if((y-1) > 0 && map[y-1][x] !=1) {
Node newNode = new Node(x, y-1, map[y-1][x], node);
if(onClosedList(newNode) == false) {
newNode.setG(node.getG()+10);
newNode.setH(manhattanDist(newNode, endNode));
newNode.setF(newNode.getG()+newNode.getH());
if(checkAndReplaceOpen(newNode, node, false) == false)
openQ.add(newNode);
}
}
if((y+1) < map.length && (x+1) < map[y].length && map[y+1][x+1] !=1) {
Node newNode = new Node(x+1, y+1, map[y+1][x+1], node);
if(onClosedList(newNode) == false) {
newNode.setG(node.getG()+14);
newNode.setH(manhattanDist(newNode, endNode));
newNode.setF(newNode.getG()+newNode.getH());
if(checkAndReplaceOpen(newNode, node, true) == false)
openQ.add(newNode);
}
}
if((y+1) < map.length && (x-1) >= 0 && map[y+1][x-1] !=1) {
Node newNode = new Node(x-1, y+1, map[y+1][x-1], node);
if(onClosedList(newNode) == false) {
newNode.setG(node.getG()+14);
newNode.setH(manhattanDist(newNode, endNode));
newNode.setF(newNode.getG()+newNode.getH());
if(checkAndReplaceOpen(newNode, node, true) == false)
openQ.add(newNode);
}
}
if((y-1) > 0 && (x-1) >= 0 && map[y-1][x-1] !=1) {
Node newNode = new Node(x-1, y-1, map[y-1][x-1], node);
if(onClosedList(newNode) == false) {
newNode.setG(node.getG()+14);
newNode.setH(manhattanDist(newNode, endNode));
newNode.setF(newNode.getG()+newNode.getH());
if(checkAndReplaceOpen(newNode, node, true) == false)
openQ.add(newNode);
}
}
if((y-1) >= 0 && (x+1) < map[y].length && map[y-1][x+1] !=1) {
Node newNode = new Node(x+1, y-1, map[y-1][x+1], node);
if(onClosedList(newNode) == false) {
newNode.setG(node.getG()+14);
newNode.setH(manhattanDist(newNode, endNode));
newNode.setF(newNode.getG()+newNode.getH());
if(checkAndReplaceOpen(newNode, node, true) == false)
openQ.add(newNode);
}
}
}
private Node solve() {
Node startNode = new Node(startX, startY, 0, null);
startNode.setH(manhattanDist(startNode, endNode));
startNode.setF(startNode.getG() + startNode.getH());
openQ.add(startNode);
while(openQ.isEmpty() == false) {
Node currNode = openQ.remove();
closedQ.add(currNode);
if(currNode.getX() == endX && currNode.getY() == endY) {
return currNode;
}
addNeighbors(currNode);
}
System.out.println(“No solution found!”);
return startNode;
}
public LinkedList<Node> algorithm() {
LinkedList<Node> pathr = new LinkedList<Node>();
LinkedList<Node> path = new LinkedList<Node>();
Node addNode = solve();
while(addNode.getParent() != null) {
pathr.add(addNode);
addNode = addNode.getParent();
}
pathr.add(addNode);
while(pathr.isEmpty() == false)
path.add(pathr.removeLast());
return path;
}
public void printList(LinkedList<Node> list) {
Iterator<Node> it = list.iterator();
while(it.hasNext())
System.out.println(it.next());
}
}